Welcome to the Splogosphere
December 16, 2005
Welcome to the Splogosphere!
UMBC study estimates that 75% of posts to English language weblogs are spam
Baltimore, December 16, 2005
A weblog monitoring system developed by UMBC Ph.D. student Pranam Kolari shows that a new form of spam -- spam blogs or splogs -- has quickly become a serious problem.
Splogs are "fake" weblog sites that have been set up to carry paid advertisements, promote affiliated web sites by increasing their PageRank, and to get new sites noticed by search engines. The content included in the splogs is typically random nonsense text, text plagiarized from other websites or content hijacked from other blogs. Most of these splogs are created and maintained automatically.
A part of Kolari's Ph.D. research he has implemented Memeta -- a system to discover blogs, monitor their activity and build up a database of metadata about them. Memeta currently has information on over six million blogs worldwide. As part of the metadata analysis, his system identifies the blog's language and also categorize it as being a legitimate blog or a splog. These modules were developed using machine learning techniques from artificial intelligence that base their judgment on blog's text content, but also it's structure and relationships to other blogs and web sites. The machine learning approach allows these modules to be periodically retrained so that they will adapt and maintain their accuracy as blog usage changes. Kolari estimates that Memeta's current accuracy at language identification at 99% and about 90% for splog identification.
Using his system, Kolari analyzed all new blogs posts collected using a web service offered by weblogs.com. Over the last four weeks over 40 million posts from about 14 million blogs were analyzed. The study shows that 75% of these posts were from blogs judged to be splogs. As shown in the charts below pings from blogs average around 8K per hour and those from splogs average around 25K.

25% of blog posts are from from legitimate blogs

75% of posts are from from spam blogs
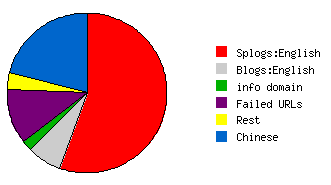
Of the 14 million sources which pinged weblogs.com during the study, splogs made up more than half, shown in this graph.
A paper on Memeta will be presented in March at the AAAI Spring Symposium on Computational Approaches to Analyzing Weblogs. Hourly data from Memeta is available online. For more information, contact memeta@ebiquity.umbc.edu.
The techniques being explored by Kolari and others at the UMBC ebiquity research group can be used by web and blog search engines such as Google and Technorati to identify posts from splogs and remove them from their search results.
For more information, please contact UMBC ebiquity.